
第一章 单元测试
1、单选题:
什么是KDD?( )
选项:
A:动态知识发现
B:数据挖掘与知识发现
C:文档知识发现
D:领域知识发现
答案: 【数据挖掘与知识发现】
2、判断题:
数据挖掘分析是指从海量的数据中抽取感兴趣的(有价值的、隐含的、以前没有用但是潜在有用信息的)模式和知识。( )
选项:
A:对
B:错
答案: 【对】
3、多选题:
数据挖掘分析的步骤包括( )
选项:
A:算法分析
B:创建数据集
C:模型评估
D:数据预处理
答案: 【算法分析;
创建数据集 ;
模型评估;
数据预处理】
4、判断题:
当今社会,数据挖掘分析被广泛应用。( )
选项:
A:对
B:错
答案: 【对】
5、多选题:
( )是未来大数据分析的发展趋势。
选项:
A:可视化
B:简单
C:非结构化数据
D:实时性
答案: 【可视化;
非结构化数据;
实时性】
第二章 单元测试
1、多选题:
关于描述统计,包括( )。
选项:
A:离中趋势分析
B:相关分析
C:集中趋势分析
D:其余选项都不是
答案: 【离中趋势分析;
相关分析;
集中趋势分析】
2、单选题:
以下属于推断统计的是( )。
选项:
A:集中趋势分析
B:参数估计
C:离中趋势分析
D:其余选项都不是
答案: 【离中趋势分析】
3、多选题:
在数据特征的测度中,描述分布的形状的值为( )
选项:
A:中位数
B:偏态
C:峰态
D:众数
答案: 【偏态;
峰态】
4、判断题:
测度集中趋势就是寻找数据水平的代表值或中心值( )
选项:
A:对
B:错
答案: 【对】
5、判断题:
四分位数可以用于顺序数据、数值数据和分类数据( )
选项:
A:错
B:对
答案: 【错】
第三章 单元测试
1、单选题:
下面哪个属于映射数据到新的空间的方法? ( )
选项:
A:傅立叶变换
B:渐进抽样
C:维归约
D:特征加权
答案: 【】
2、单选题:
将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?( )
选项:
A:分类和预测
B:数据预处理
C:数据流挖掘
D:频繁模式挖掘
答案: 【】
3、单选题:
影响数据质量问题的因素有哪些( )
选项:
A:其余选项都对
B:相关性、时效性
C:准确性、完整性、一致性
D:可信性、可解释性
答案: 【】
4、多选题:
数据预处理的常见方法有( )
选项:
A:数据清洗
B:其余选项都不对
C:数据变换
D:数据集成
答案: 【】
5、判断题:
数据预处理是指在对数据进行挖掘分析以前,需要对原始数据进行清理、集合和变换等一系列处理工作( )
选项:
A:错
B:对
答案: 【
第四章 单元测试
1、单选题:
考虑下面的频繁3-项集的集合:{1,2,3},{1,2,4},{1,2,5},{1,3,4},{1,3,5},{2,3,4},{2,3,5},{3,4,5}假定数据集中只有5个项,采用 合并策略,由候选产生过程得到4-项集不包含( )
选项:
A:1,2,3,5
B:1,2,3,4
C:1,3,4,5
D:1,2,4,5
答案: 【】
2、单选题:
频繁项集、频繁闭项集、最大频繁项集之间的关系是: ( )
选项:
A:频繁项集 频繁闭项集 最大频繁项集
B:频繁项集 = 频繁闭项集 = 最大频繁项集
C:频繁项集 = 频繁闭项集 最大频繁项集
D:频繁项集 频繁闭项集 =最大频繁项集
答案: 【】
3、单选题:
某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖掘的哪类问题?( )
选项:
A:分类
B:自然语言处理
C:聚类
D:关联规则发现
答案: 【】
4、单选题:
下面购物篮能够提取的3-项集的最大数量是多少( )ID 购买项1 牛奶,啤酒,尿布2 面包,黄油,牛奶3 牛奶,尿布,饼干4 面包,黄油,饼干5 啤酒,饼干,尿布6 牛奶,尿布,面包,黄油7 面包,黄油,尿布8 啤酒,尿布9 牛奶,尿布,面包,黄油10 啤酒,饼干
选项:
A:4
B:2
C:1
D:3
答案: 【】
5、多选题:
Apriori算法的计算复杂度受( )影响。
选项:
A:事务数
B:项数(维度)
C:事务平均宽度
D:支持度阀值
答案: 【】
第五章 单元测试
1、单选题:
以下哪些算法是分类算法,( )
选项:
A:DBSCAN
B:EM
C:C4.5
D:K-Mean
答案: 【】
2、单选题:
决策树中不包含一下哪种结点, ( )
选项:
A:外部结点(external node)
B:根结点(root node)
C:叶结点(leaf node)
D:内部结点(internal node)
答案: 【】
3、单选题:
以下哪项关于决策树的说法是错误的 ( )
选项:
A:寻找最佳决策树是NP完全问题
B:冗余属性不会对决策树的准确率造成不利的影响
C:子树可能在决策树中重复多次
D:决策树算法对于噪声的干扰非常敏感
答案: 【】
4、单选题:
以下关于人工神经网络(ANN)的描述错误的有 ( )
选项:
A:神经网络对训练数据中的噪声非常鲁棒
B:训练ANN是一个很耗时的过程
C:可以处理冗余特征
D:至少含有一个隐藏层的多层神经网络
答案: 【】
5、多选题:
贝叶斯信念网络(BBN)有如下哪些特点, ( )
选项:
A:贝叶斯网络不适合处理不完整的数据
B:对模型的过分问题非常鲁棒
C:网络结构确定后,添加变量相当麻烦
D:构造网络费时费力
答案: 【
6、单选题:
如下哪些不是最近邻分类器的特点, ( )
选项:
A:分类一个测试样例开销很大
B:可以生产任意形状的决策边界
C:最近邻分类器基于全局信息进行预测
D:它使用具体的训练实例进行预测,不必维护源自数据的模型
答案: 【】
第六章 单元测试
1、多选题:
( )这些数据特性都是对聚类分析具有很强影响的。
选项:
A:噪声和离群点
B:高维性
C:规模
D:稀疏性
答案: 【】
2、单选题:
考虑这么一种情况:一个对象碰巧与另一个对象相对接近,但属于不同的类,因为这两个对象一般不会共享许多近邻,所以应该选择( )的相似度计算方法。
选项:
A:直接相似度
B:余弦距离
C:平方欧几里德距离
D:共享最近邻
答案: 【】
3、单选题:
在基本K均值算法里,当邻近度函数采用( )的时候,合适的质心是簇中各点的中位数。
选项:
A:余弦距离
B:平方欧几里德距离
C:曼哈顿距离
D:Bregman散度
答案: 【】
4、单选题:
简单地将数据对象集划分成不重叠的子集,使得每个数据对象恰在一个子集中,这种聚类类型称作( )
选项:
A:模糊聚类
B:层次聚类
C:非互斥聚类
D:划分聚类
答案: 【
5、判断题:
K均值是一种产生划分聚类的基于密度的聚类算法,簇的个数由算法自动地确定。( )
选项:
A:错
B:对
答案: 【】
第七章 单元测试
1、多选题:
可视化涉及到的学科包括( )
选项:
A:人机交互
B:计算机图形学
C:数据挖掘
D:统计分析
答案: 【】
2、单选题:
若有一个数据集,每个数据点有5个属性,以下哪种可视化技术最适用于表示其属性凉凉之间的相关性呢?( )
选项:
A:散点图
B:直方图
C:像素图
D:坐标系
答案: 【
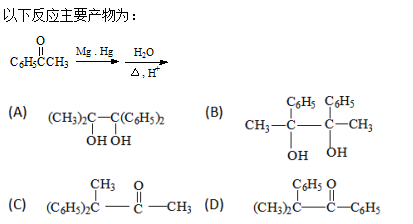
3、单选题:
下图主要运用了哪一种基本可视化图表?( )
选项:
A:盒须图
B:折线图
C:走势图
D:散点图
答案: 【
4、判断题:
echars可以用来实现大数据可视化大屏( )
选项:
A:错
B:对
答案: 【】
5、判断题:
数据可视化是大数据发展的趋势。( )
选项:
A:错
B:对
答案: 【】

评论0